My own particular interest in flow systems is the management of agile software development teams, usually using some variant of Scrum and/or Kanban, and other agile practices such as test-driven (or automated-test intensive) build-test-deploy processes. However the discussion is relevant in many other domains, such as one I've recently been involved in discussing, the flow of patients through diagnosis, treatment and convalescence in healthcare systems.
In managing these systems we need ways to look at the mass of data that emerges from them to focus on the useful information rather than the noise; information in particular that indicates when intervention is appropriate to improve flow, and when the attempt would be as futile as trying to smooth the waves on an ocean. Flow systems in knowledge work contain variability. That variability, within certain bounds (much wider bounds than in manufacturing for example), is desirable to allow innovation, responsiveness and minimising wasteful planning activities.
In this context Flow Debt is a measure that provides a view of what is happening inside our system. This is in contrast with other important measures such as Throughput (Th) and the time an item stays in the process (I call this "Time in Process", TiP [macc], though other terms may be used). These measures provide information only after items have left the system, which may be too late to avoid problems accumulating.
Having Flow Debt roughly translates as: delivering more quickly now at the cost of slower times later. It is calculated by comparing the time since the number of arrivals into the systems was equal to the current number of deliveries with the average time in the process for the most recent deliveries. It is easiest to visualise this on a Cumulative Flow Diagram.

At the point highlighted in the the diagram it is a little over 2 weeks since the cumulative number of items entering the system equalled the cumulative number of deliveries on that date. If the items were delivered in the precise order they arrived, and if all the items were delivered (neither assumption is true!), then we would be able to say that the time the last item spent in the process was also a little over 2 weeks. Furthermore if arrivals and deliveries were smooth over the period, the Average Time in Process for the items would also be this same time.
What was the actual Average Time in Process though? Well you can't read this off the diagram. You have to look at the average TiP for the items delivered in the recent period. Each one has a known TiP, so take the average of them. Exactly how long the period you select for this average is up to you - a day or a week seems reasonable. The shorter the period you take the more noise there will be in the signal. Take too long a period though and there is insufficient time to act on the information.
With this information we can calculate Flow Debt using Dan's method[vaca]:
Flow Debt = (Time since number of arrivals equalled deliveries) - Average TiP
If you plot this quantity for the data above you get a graph like this. Note I've reversed the sign on this graph to show Flow Debt as negative.

The plot of Flow Debt in this case is quite normal showing a fluctuation around zero and maxima and minima of around the value of the average TiP for the whole period. If you plotted the same data with a monthly average, most of this fluctuation would disappear. I certainly wouldn't want managers rushing down to this team to radically change their process!
There is one point highlighted which is interesting, where the Flow Debt goes from highest debt to highest credit in a few days. What do you think is going on here? Well, if you go back to the informal definition of Flow Debt (delivering more quickly now at the cost of slower times later), we should surmise that before this point the delivered items had been in the process for only a short time. Those delivered at or after this point had a longer time in the process. That's exactly what happened, as the Control Chart below shows.
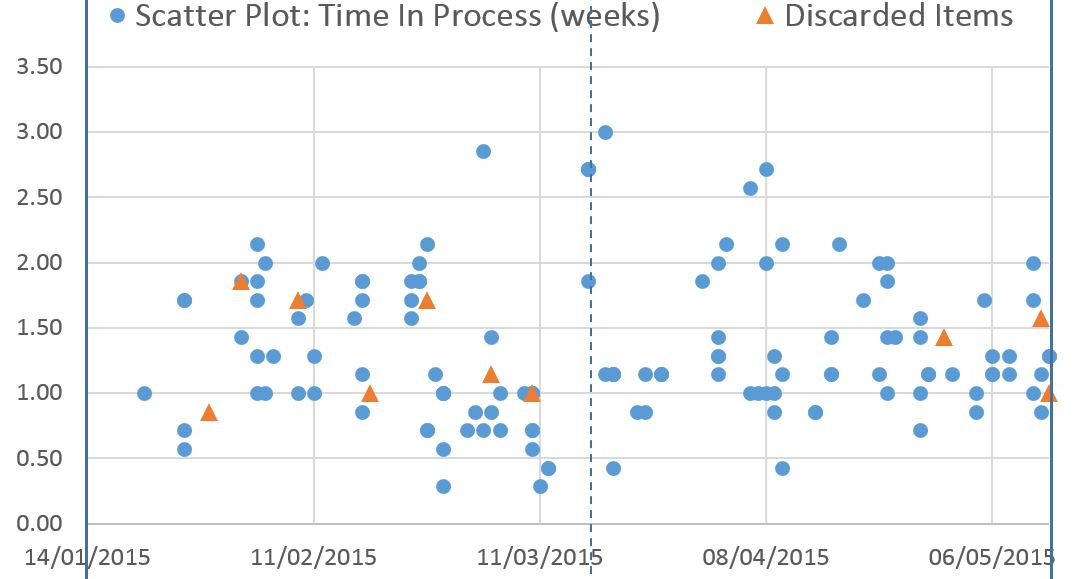
Another useful indicator here is the "average age" of the work in progress. Here is the plot of that and you can see the significant drop in this metric at the same point.

Just by way of balance let's look at another data set of a team delivering software much less frequently, where their work in progress is increasing over the process, and where the items are not being delivered in age order. All these factors are likely to effect the efficiency and predictability of the flow system... and this is borne out by their plot of Flow Debt.

Seeing a plot like this is a indication to management (and flow management specialists in particular) to take a much closer look at the process being used here.
References
- [macc] Maccherone, Larry. Introducing the Time In State InSITe Chart. LSSC. (2012)
- [vaca] Vacanti, Daniel S. Actionable Agile Metrics for Predictability: An Introduction, LeanPub. (2015)